
智东西(公众号:zhidxcom)
文 | Lina
智东西5月23日下午,今天,世界围棋第一人柯洁与DeepMind旗下的AlphaGo进行了一场长达4个半小时的围棋对战,最终柯洁仅以1/4子的差距惜败AlphaGo,这场从上午10点半开始的鏖战终于告一段落。
这是本次围棋大赛中柯洁对战AlphaGo三场比赛中的头一场,柯洁执黑先行。与年初披着“Master”马甲的连胜60场时不同,这次“柯Go大战”下的是每方时长3小时的慢棋,而不是每手30秒快棋,对人类有着一定优势。
理论上本轮比赛将持续3+3=6小时,但最终柯洁几近耗尽3小时,AlphaGo仅用了1个多小时。比赛后期柯洁频频有咬嘴唇、抓头发等焦虑的小动作,看得观众也不禁紧张起来。在最终只剩十几分钟、败局已定时,柯洁仍坚持下完全局。

(赛事焦灼时的柯洁)

(观棋室里人山人海,由专业围棋家进行讲解)
AlphaGo是由DeepMind团队的戴密斯·哈萨比斯、大卫·席尔瓦、黄士杰等开发的一款人工智能程序。2016年3月,AlphaGo曾以5:3战胜韩国棋手李世石,成为第一个击败人类职业围棋选手的电脑程序。2016年12月底,AlphaGo身披“Master”马甲,5天内横扫中日韩棋坛,最终以60场连胜纪录告退。
读完本文,你可以知道以下问题的答案:
1)年初不是PK过了吗?怎么又来?
2)为什么AI老盯着围棋不放?
3)AlphaGo到底是怎么下棋的?(最通俗易懂版本解释)
4)德扑、围棋、象棋,下一个被AI入侵的领域是啥?
5)AlphaGo的技术有什么现实意义?

(10点半开场第一手)
其实,柯洁与AlphaGo的这场比赛开始前,胜率并不被多少人看好。就连柯洁本人在四月初的发布会上,也用上了“怀有必死的信念,不会轻易言败”这种情怀悲壮的词语,昨夜11点半更是在微博发布了一条名为《最后的对决》的赛前感言。

“无论输赢,这都将是我与人工智能最后的三盘对局”
“现在的AI进步之快远超我们的想象。像国产的绝艺、日产的ZEN虽然和AIphago还有着较大差距,但已经表现出超强的实力了…”
“我相信未来是属于人工智能的。可它始终都是冷冰冰的机器,与人类相比,我感觉不到它对围棋的热情和热爱……”
如此沉重,如此伤怀,很难想象这是曾经意气风发的天才少年。去年3月9日李世石1:4落败AlphaGo时,年仅19岁的他曾在微博放出豪言——“就算阿法狗战胜了李世石,但它赢不了我”,彼时尚不知柯洁是何方神圣的吃瓜群众对其一顿群嘲,接着立刻被刷刷刷一溜世界冠军的履历反转打脸的剧情看得人大呼过瘾。国内大众向来是偏爱柯洁的,我们都爱听传奇故事,爱看任性的少年天才打破陈规,扬名立万,如同起点网文一般的人生赢家。
此役战败,着实让人唏嘘不已。
其实,这并不是柯洁与AlphaGo的第一次交手。
2016年12月底,一位身披Master马甲的神秘棋手突然出现,5天内横扫中日韩棋坛,包括当时年仅19的三次世界大赛冠军柯洁九段(今年20岁)、韩国等级分第一朴廷桓九段、中国名人战冠军连笑七段等,甚至激起了业内64岁泰斗聂卫平参战,最终在连胜60场后宣告揭晓真身——就是AlphaGo。

既然已经PK过了,为什么又要比一次呢?
原来在年底时,Master与各位棋手下的是30秒快棋,对于拥有强大计算能力的电脑来说,优势非常明显。而本次柯洁 vs AlphaGo下的是慢棋,有3小时的思考时间,对于人类比较有利。
此外,本次柯洁与AlphaGo下的是“三番棋”,无论输赢都将下满三局,下两轮比赛将分别在本周四(25号)与本周六(27号)的同一时间进行,大赛同时还设有150万美元奖金。
很多人其实都对AlphaGo下棋的套路存在误会,认为它是程序嘛,那用最简单(最暴力)的方法——穷举,自然是最有效的。
也……不是不行。但我们先来算算穷举一共会出现多少情况。
普林斯顿研究人员曾经做过这样一个统计项目,对于一个标准的围棋棋盘而言,一共有19×19=361个位置,每个位置存在黑子、白子、空,3种情况。因此一局棋面理论上有3^361种可能。但根据围棋规则,不是所有位置都可合法落子,因此在排除掉所有不合法的棋局后,精确的合法棋局数为——
……
你真的想知道吗?……
深呼吸……
……
208168199381979984699478633344862770286522453884530548425639456820927419612738015378525648451698519643907259916015628128546089888314427129715319317557736620397247064840935局。
让一台计算机暴力算法穷举……也不是不行,普林斯顿的研究人员这么试过一遍,使用15TB硬盘空间、8-16核处理器、192GB内存的服务器将这约等于2.08×10^170局棋全部穷举出来,大概需要几个月的时间。按3个月来算的话,如果AlphaGo按照这个配置每下一步棋都将所有情况穷举一遍,那么这盘棋下完的时候,今年20岁的柯洁已经是六十多岁的老人家了……
当然啦,上文的这个比喻有些偷换概念,而且AlphaGo的配置比这要高出许多。当年和李世石下棋时,AlphaGo配备了1920个CPU加280个GPU,如今经过一年多的软硬件升级,自然将计算能力武装到了牙齿。
不过,AlphaGo用的真的不是穷举,而是一套结合了深度学习(Deep Learning)与增强学习(Reinforcement Learning)的系统。DeepMind团队在《自然》杂志上发表的《用深度神经网络和树搜索掌握围棋博弈(Mastering the Game of Go with Deep Neural Networks and Tree Search)》论文中详细介绍了AlphaGo是怎么下棋的,此处不展开讲了,只做一个粗浅的流程介绍:
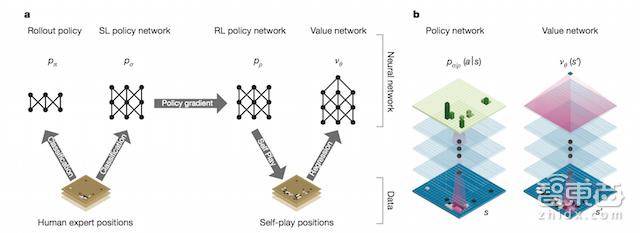
1)分析专业棋手棋谱,得到两个结果,快速走棋策略(Rollout Policy)与策略网络(SL Policy Network)。其中快速走棋策略类似于人观察盘面获得的“直觉”,使用线性模型训练;策略网络则经过深度学习模型训练进行分析,类似于人类的“深思熟虑”。
2)用新的策略网络与先前训练好的策略网络互相对弈,利用增强学习来修正参数,最终得到增强的策略网络(RL Policy Network),类似于人类左右互搏后得到一个“更加深思熟虑”的结果,对某一步棋的好坏进行判断。
3)将所有结果组成一个价值网络(Value Network),对整个盘面进行“全局分析”判断,图中蓝色越深的位置赢面越大,这样可以让程序有大局观,不会因蝇头小利而输掉整场比赛。
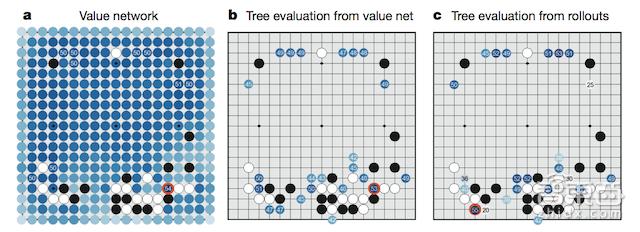
4)综合“直觉”、“深思熟虑”、“全局分析”的结果进行评价,循环往复,找出最优落子点。
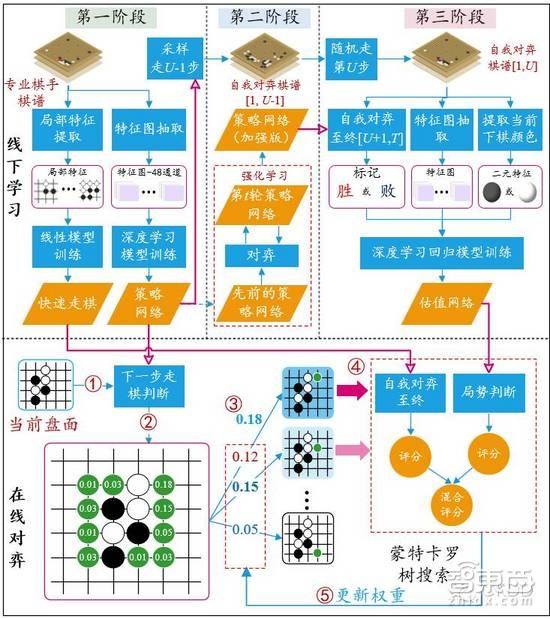
微软亚洲研究院主管研究员郑宇与微软亚洲研究院副研究员张钧波在多次论文阅读原文并收集了大量其他资料后,一起完成了一张更为详细的AlphaGo原理流程图,此处转载作以解释,版权归两位作者所有。
AlphaGo中的“Go”,在英语中就是“围棋”的意思,AlphaGo顾名思义就是一款专门为围棋打造的程序。不过,DeepMind团队曾经透露下一阶段会转移目标,向暴雪的即时战略游戏《星际争霸》发起挑战,再次志得意满之后,星际的高手们请作好心理准备,下一个擂台可能就是发生在人族、神族和虫族的世界里了。
其实早在2013年,DeepMind就在NIPS上发表《用深度增强学习玩Arari游戏(Playing Atari with Deep Reinforcement Learning)》这一论文让机器像人类一样玩Atari游戏,即只接收屏幕像素输入,也只产生视频游戏控制器上的按压信号,也算是个热爱玩游戏的AI团队了。

其实从第一台计算机问世以来,人们就不停尝试着编写更加强大高效的计算机程序,以期电脑有朝一日能够战胜人类。在过去的二十多年里,有好次次人机大战给人们留下深刻的印象。
1997年5月,IBM公司的“深蓝”超级计算机以2胜1负3平的战绩战胜了当时的世界国际象棋大师冠军——卡斯帕罗夫(ГарриКимовичКаспаров)。其实从今天看来,“深蓝”还算不上足够智能,主要依靠强大的计算能力穷举所有路数来选择最佳策略。当时的“深蓝”每秒可运算2亿步,在全球超级计算机中排第259位。

据说在比赛中,第二局的完败让卡斯帕罗夫深受打击,他的斗志和体力在随后3局被拖垮,在决胜局中仅19步就宣布放弃。IBM拒绝了卡斯帕罗夫的再战请求,拆卸了“深蓝”,因而卡斯帕罗夫后来虽多次与电脑战平,却无法再找深蓝“复仇”。
2011年,与“深蓝”同样出自IBM公司的人工智能程序“沃森”在美国老牌智力问答节目《危险边缘》中挑战两位人类冠军。“沃森”存储了2亿页的数据,其中包括了各种百科全书、新闻、词典、文学书籍等,还能根据比赛奖金的数额、局面的领先或落后情况、自己是否擅长该领域的问题来判断自己是否要抢答某一个问题。最终,沃森轻松战胜两位人类冠军。
在今年1月20日《最强大脑》人机大战第三场的比赛中,百度大脑2比0轻松战胜人类选手王昱珩。在这场比赛中,百度大脑和“水哥”王昱珩比拼的仍然是图像识别。通过三段在夜幕下分别从行车记录仪、高位摄像头、和手机中拍到的模糊动态影像,双方需要记住三名不同识别对象的面部特征,然后从节目现场的30人中将他们辨认出来。
此外,还有今年4月初由李开复发起,创新工场、海南生态软件园联合主办的“冷扑大师”VS“龙之队”德州扑克人机大战。

“冷扑大师”的前身来自于耐基梅隆大学(Carnegie Mellon University,以下简称CMU)Tuomas Sandholm教授领导开发的打扑克的程序Libratus。在今年1月30日,Libratus曾一对一无限注德州扑克比赛中击败四名顶尖人类高手,在为期20天的赛程里面对玩12万手,赢走接近总数的筹码。人类团队由由六位华人顶尖扑克选手组建,队长杜悦曾在世界德州扑克大赛WSOP的无限注德州扑克赛事中获得冠军。
最终,比赛以冷扑大师完胜人类结局。李开复在赛后也曾断言,“人工智能已从完美信息的AlphaGo,延伸到了不完美信息的冷扑大师。人机对战基本没有悬念了,据闻AlphaGo近期即将来华和柯洁对战,其实已经不再具有科学意义了。 ”
其实,AlphaGo并不是DeepMind唯一项目,也不是最大的项目。DeepMind的最终目标是智能助手、医疗和机器人等。Scott Beaumont曾经在4月初的发布会上表示,尽管AlphaGo只是针对围棋开发的系统,但其原理可以被应用到现实问题中,比如医疗中的癌症检测、机器人训练等。

与单纯的深度学习应用不同,AlphaGo在系统中加入了增强学习的部分。增强学习不一定为机器设定特殊明确的行为,机器试探性地做一个行动后,观察“世界”会有怎样的反应(奖赏还是惩罚),最终逐步形成对刺激的预期,产生能获得最大利益的习惯性行为。这个方法具有普适性,因此在其他许多领域都有研究,但比较集中在步骤可能性较少、任务行为较窄的领域(比如围棋、简单物理运动等)。英伟达CEO黄仁勋在月初的GTC大会上就宣布了一款名为ISAAC的增强学习世界模拟器,创造出一个完全虚拟的、专为训练机器人而打造的世界,用来训练机器人执行打冰球、打高尔夫等动作。
无论最后两局胜负如何,人工智能最终在围棋上战胜人类已然是可预见的将来。即便这场三番棋赛柯洁最终获胜,也无法逆转这种潮流,也许明年,也许后年,但总有一日终将到来——就如同当年一匹世界最快的良驹宝马,最终也无法跑赢汽车。
正如柯洁所言,“我相信未来是属于人工智能的。”
但话说回来,AlphaGo的胜利意味人类要完蛋?别闹了,围棋可不是我们生活的全部,人工智能也只是一项用于改善人类生产效率的工具而已。对于许多科幻小说里提出的,最终能够“推翻人类”、“统治人类”的“超级智能”,我们真的大可不必太担心。

(Yann LeCun)
“卷积神经网络之父”、深度学习三巨头之一、Facebook人工智能研究院院长Yann LeCun曾经这样解释道,人类的占领、统治、斗争等大部分行为,都是在一代代进化的过程中,受到“希望获得资源”这一目的所驱动的。而如果我们想要机器做一件事情,则需要给它赋予这个能力,朝这个目的去打造机器。如今我们已经做出了在特定领域比人类更智能的机器,但人工智能并不会真正统治世界,因为我们并不会朝这个目的去做。
在火车刚刚发明的时候,美国某位权威人士曾经预言:“如果美国建设铁路,首先要建许多家精神病院,因为人们看见呼啸而过的火车会被吓破胆的。”
而德国的专家们则说,“火车时速一旦超过15英里,鲜血就会从乘客的鼻腔里喷射出来,导致死亡。”




















